
An AI copilot that works with your company’s knowledge and data can be implemented in minutes today. But where do you look for data or content in your organization to train AI support, and what rules should you know and obey before you feed anything to AI? Read on to find out.
Forget about the heavily hallucinating Gen AIs of yesteryear. With the new RAG-based solutions, like our Copilot, you set upt and train AI support chatbot give precise, actionable answers based on your company’s knowledge and data. And you can have them up and running in minutes. This is no longer experimenting with LLMs; it is a proven way to turn static documents into a living organism of knowledge and support – your copilot.
Yes, but RAG is designed to minimize hallucinations – one of the best things about RAG-based AI chatbot is, that when it does not know the answer, it says “i do not now” rather than making something up.
Deploying LLMs on internal knowledge is not a one-off tech stunt but a significant step in digital transformation. It brings faster search, lower support costs, new revenue streams, quicker onboarding, regulatory confidence, and the option to automate entire processes. Let’s look at how to embark on this journey and how to choose and prepare corporate data and knowledge for it.
What Is RAG (Retrieval-Augmented Generation)?
TLDR: A RAG model works by first using the LLM to understand the query. Then, the LLM uses this understanding to retrieve relevant information from a database. The LLM then generates a response based on the retrieved information and sends the answer back to the user, ideally with links to the source documents.
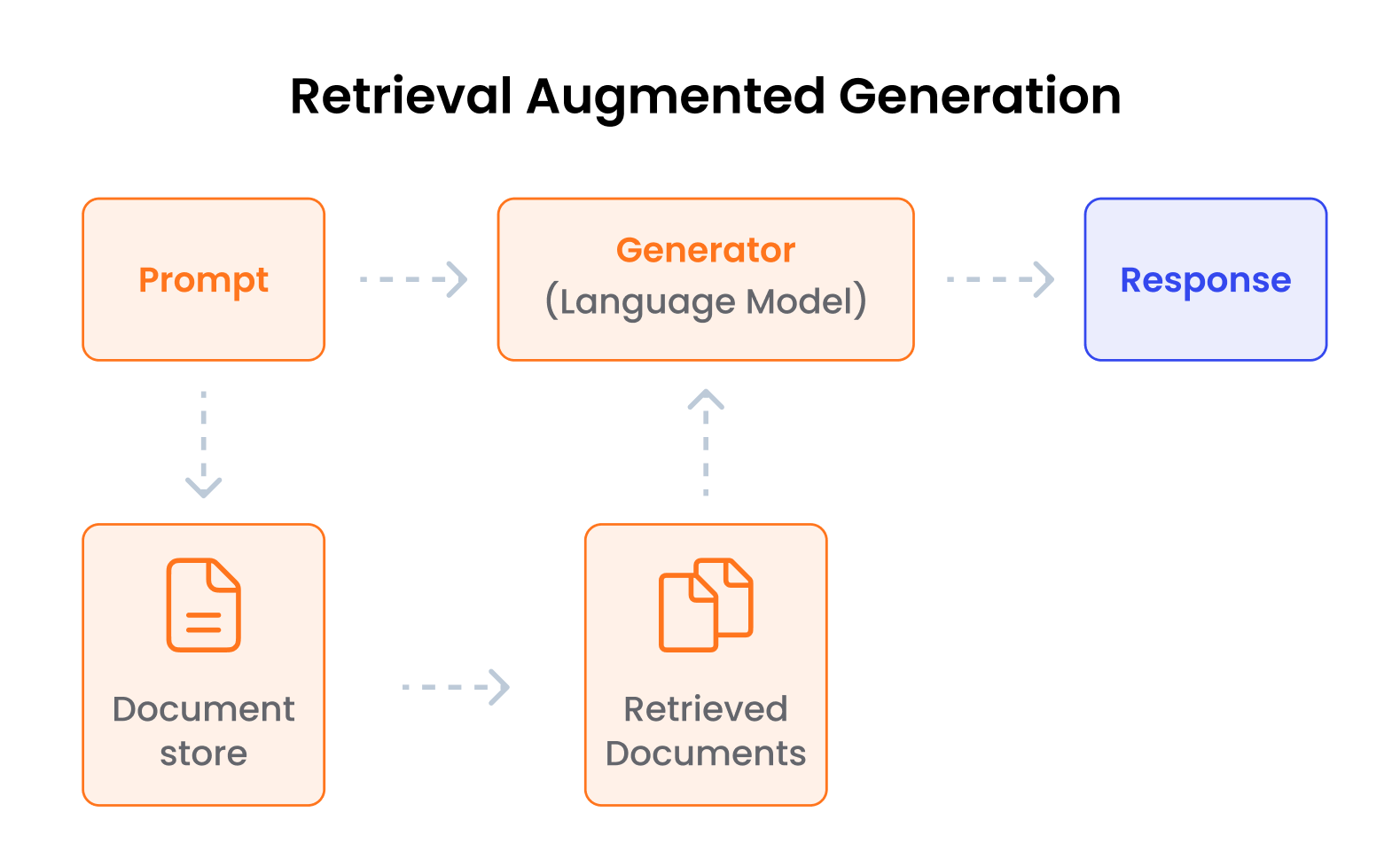
So what is RAG, in detail? Of course there is nice but rather technical explanation on Wikipedia:
“RAG improves large language models (LLMs) by incorporating information retrieval before generating responses.Unlike traditional LLMs that rely on static training data, RAG pulls relevant text from databases, uploaded documents, or web sources.” Wikipedia: Retrieval-augmented generation
How that translates to real life use:
RAG is a fast, secure, and cost-effective way to turn years of accumulated company know-how into a live AI adviser—available 24/7—without the massive investment of building an AI model or solution from scratch. By combining large language models (LLMs) with your own data, RAG:
It works just as well for internal knowledge sharing as it speeds up external customer support on the web or SaaS products. Think of RAG as a blend of a world-class search engine and generative AI. Before the model “starts writing,” it pulls the most relevant excerpts from your internal knowledge base, manuals, databases, or any other sources you specify. Those excerpts are then attached to the prompt, so the LLM works strictly with verified company data instead of a fuzzy memory scraped from the internet. You can therefore trust that answers are factually correct, properly cited, and quickly adjust to any documentation change, with no time-consuming model retraining.
This is no longer an experiment or AI tinkering. It is a way to turn static documents into a living organism of knowledge and support:
The most visible benefit is the radical acceleration of information search. Instead of trawling through wikis, shared drives, or PDF manuals, employees and customers can ask questions in natural language and receive, within seconds, a clear, summarised answer—complete with citations and a step-by-step guide. Search time drops sharply, the help desk sheds first-line routine tickets, and AI agents can automatically:
Support staff are freed to do creative, hands-on tasks with higher added value.
The same applies to user onboarding for SaaS platforms, hiring and ramping up new employees (from admin setup to understanding core processes), and ongoing training and education. Add instant localisation of documentation or outputs into dozens of languages—while preserving professional terminology—and you have a tool that removes communication barriers and speeds global expansion.
Suppose you have the green light to implement an AI-based copilot (such as the one offered within the Product Fruits user onboarding and digital adoption platform). In that case, you need to assess your organization’s suitable material, as this will be knowledge and data on which Copilot can answer, explain, or recommend effectively.
A knowledge audit is not paperwork; it is the process of turning existing material, with varying effort, into a corpus from which the language model inside Copilot will later draw. Maybe you already have a knowledge base or other body of knowledge used by your tech/user support, or other materials such as product or technical manuals, or transcripts from resolved tech support cases. In such a case, lucky you!
All you need to do is check if it is structured in a way that the AI RAG solution, such as our Copilot can leverage. Read more about the proper structure of content for AI in our previous Blog post.
If you do not have a ready-made treasure trove of organized knowledge, do not despair. Building it is relatively straightforward (and you can use AI for some of it as well). In most smaller organizations, this may be a solo job, but in larger ones, consider roles such as content owner, who is accountable for content and quality, data steward, who handles metadata and versions, and possibly the involvement of the security team and some overall project lead.
So, what other relevant documents and data sources, varying in their degree of „readyness“ and suitability, may there be? Start by answering:
Remember that some content and other materials may include sensitive private information or valuable business data, so the third question that may also be relevant is:
A clearly defined goal and scope can save weeks of work. It points you to the most valuable types of content and might help you answer many questions in this and later stages.
You should address this early on when looking for and inventorying knowledge that will be available to the AI chatbot. Think about personal data protection, intellectual property, and similar issues – if you want to provide any content containing this to Copilot, you must first edit the sensitive data.
| Domain | Typical risks | Regulations/standards |
|---|---|---|
| Personal data protection | Unauthorised PII processing, data transfer outside the EU | GDPR, HIPAA, CPRA |
| Intellectual property | Copyright breach, third-party licences | EU Copyright Directive, DMCA |
| Confidentiality & classification | Trade-secret leaks, data sovereignty | ISO 27001, NIS 2 |
| Bias & discrimination | Illegal profiling, unequal treatment | EU AI Act, EEOC |
| Output safety | Toxic content, disinformation, hallucinations | ISO 42001, SOC 2 + AI components |
A well-designed legal, security, and compliance framework gives confidence that AI uses only data you can defend. It also underpins certifications like ISO 42001 or SOC 2 + AI, which are fast becoming the hygiene minimum for GenAI services.
So you already know where to look for, now is the time to go through ERP and CRM systems, incident databases, intranet wikis, network drives, and even “shadow” files in e-mails or personal OneDrive folders. Each source should be rated on five simple criteria:
Using a 1–5 scale, you will get a heat map showing quick wins—typically internal wikis and product FAQs—versus areas to avoid for technical, financial, or legal reasons.
| Content type | Examples | How to inventorize | Common risks |
|---|---|---|---|
| Structured | ERP, CRM, incident DB | Data catalogue, metadata export | Personal data, licence limits |
| Semi-structured | Confluence, SharePoint, intranet wikis | API scans, crawler, sitemap | Duplicates, context-free versions |
| Unstructured | PDF manuals, slides, e-mail archives | OCR/DLP scan, full-text crawl | Missing metadata, sensitive text |
| Multimedia | Training videos, CAD drawings, call recordings | Asset-management systems | Large volumes, format limits, and costly processing |
Next, build a prioritisation matrix: everything high-value and low-effort goes in wave 1; complex but valuable sources (legal contracts, CAD files) move to wave 2; low-gain stuff is set aside/archived for now. Handle highly sensitive content separately (e.g., in an air-gapped index or after anonymisation). Clear rules must prevent duplicates, outdated versions, or personal data from entering the source materials for Copilot. Make sure these rules eliminate any contradictions (claims, guides, information) i.e. due to differences in versions.
How long will it take?
With content that can be immediately „fed“ to the support copilot, such as an existing knowledge base or support blog with suitable structure, you can have our AI support Copilot up and running in minutes to hours, as we already mentioned. If you must find and prepare content first, the timeline may vary, from days to weeks in small startups or departments to more than a month in a mid-size company that needs to integrate lots of support content (some of which may require heavy editing).
In such cases, make sure to automate as much as possible:
If needed, outsource some tasks—but remember: it’s your data, so cover everything your team can handle.
With ready-made solutions you do not need to worry about „chunking“ your knowledge content, tagging it with metadata, and then storing each with text plus ID, version, source link, security label, and language.
For plug-and-play chatbots, neat HTML structure or Markdown pages will do the trick. The smallest unit is a single URL (which the Copilot splits internally). Your job, therefore, is to check that the heading hierarchy of your support or knowledge content is clear and, if needed, add subheadings, make/keep paragraphs short, include the correct meta description and last-modified date, and use schema tags.
Editing content into a more structured form can also be accelerated with help of GenAI, but we generally recomment to do this in smaller steps (i.e. a few paragraphs or chapter at once), with thorough prompt instructions (i.e. to avoid simplification omitting important facts/details) and carefully checking all the outputs.
In our previous post, we explained how to prepare content (i.e., write or edit articles in an online knowledge base or blog) for AI. This includes:
All this is done to ensure the LLM understands it well and answers with high precision.
Once the chatbot serves users, the real work begins: monitor whether it answers correctly, quickly, and safely, and regularly verify that sources remain fresh. You trace issues by reviewing problematic conversations and their citations, then fix the content. Without continuous monitoring, measurement, and updates, the support chatbot quality changes and may degrade over time: as your SaaS evolves, documents inevitably age, questions gradually change, and LLM models powering Copilot update.
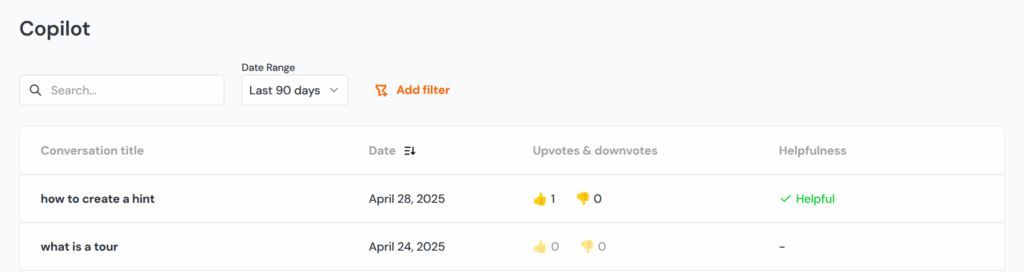
When monitoring the quality and consistency of the Copilot answers, keep in mind the non-deterministic nature of AI. No two answers are usually the same; you are looking for whether they are factually correct and grounded, not word-for-word identical.
| What you may monitor | Why it matters |
|---|---|
| Factual accuracy & groundedness | Reduce hallucinations and keep the user’s trust. |
| Relevance of retrieved snippets | Wrong snippet → wrong answer, wasted tokens |
| Latency & cost | Meet SLAs, predict budget |
| Security & legal incidents | Detect PII leaks, toxic output, and bad citations |
| User satisfaction | Measure real value (thumbs up/down, CSAT) |
AI moves fast. Soon, support Copilots will move beyond detailed and sophisticated chat. Imagine if they could actually show the user how to do a specific task (by generating a custom product or feature tour) or perform some steps for the user, with so-called agent workflows. All this will come, eventually, along with other features such as voice interactions or multimodal sources, including images and videos. The sooner you set up data and governance foundations, the easier it will be to provide these future solutions to your users.

